




在 Oracle 數據庫中,log file sync 是一個非常常見、但也極容易被誤解的等待事件。
它并不一定代表磁盤慢、也不一定是 LGWR 有問題,更多時候它反映的是 提交路徑上的“同步等待”。
本文將結合原理、架構、以及多個真實生產場景,對 log file sync 進行系統性拆解。
一、log file sync 是什么?
log file sync 表示:
前臺會話在執行 COMMIT / ROLLBACK 時,等待 LGWR 將對應 redo 寫入 redo log 文件并確認完成。
只要用戶會話沒有收到 LGWR 的“寫完成”信號,就會一直處于 log file sync 等待狀態。
二、log file sync 原理圖
1. 單實例提交路徑原理
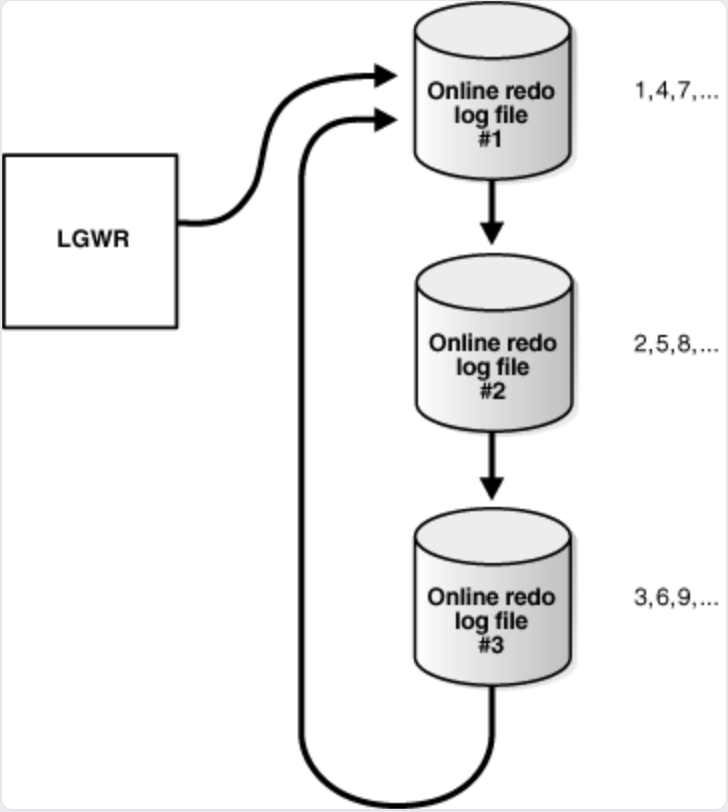
基本流程如下:
- User Session 執行
COMMIT - 提交請求通知 LGWR
- LGWR 將 redo buffer 寫入 redo log file
- 寫入成功后,LGWR 通知 User Session
- User Session 返回 commit 成功
只要第 3、4 步被拖慢,就會產生 log file sync。
三、log file sync 的主要原因分類
原因一:事務頻繁提交 / 回退(過度 commit / rollback)
1. 事務過度提交(最常見原因)
事務過度提交是引起 log file sync 等待事件的主要原因之一。
- 默認情況下,每次事務提交:
- LGWR 立即(immediate)
- 同步(wait) 寫 redo
- 提交越頻繁:
- LGWR 寫日志越頻繁
log file sync等待越明顯
本質問題不是 I/O 慢,而是 commit 太多。
解決思路
最優解(應用層):
- 將多個小事務合并為一個大事務
- 減少無意義的頻繁 commit
但現實中:
- 修改應用成本高
- 依賴應用廠商配合
DB 端可用手段(10g 以后)
Oracle 10g 起提供參數:
commit_write = nowait,batch
含義:
? 提交時不立即寫日志
? redo 采用異步 + 批量寫
?? 風險提示:
? 數據庫異常宕機時,可能丟失最近一小部分事務
? 需要業務可接受
其他輔助方式
? 使用臨時表
? 使用 NOLOGGING
? 盡可能減少 redo 產生量
原因二:存儲 I/O 資源緊張,LGWR 寫入緩慢
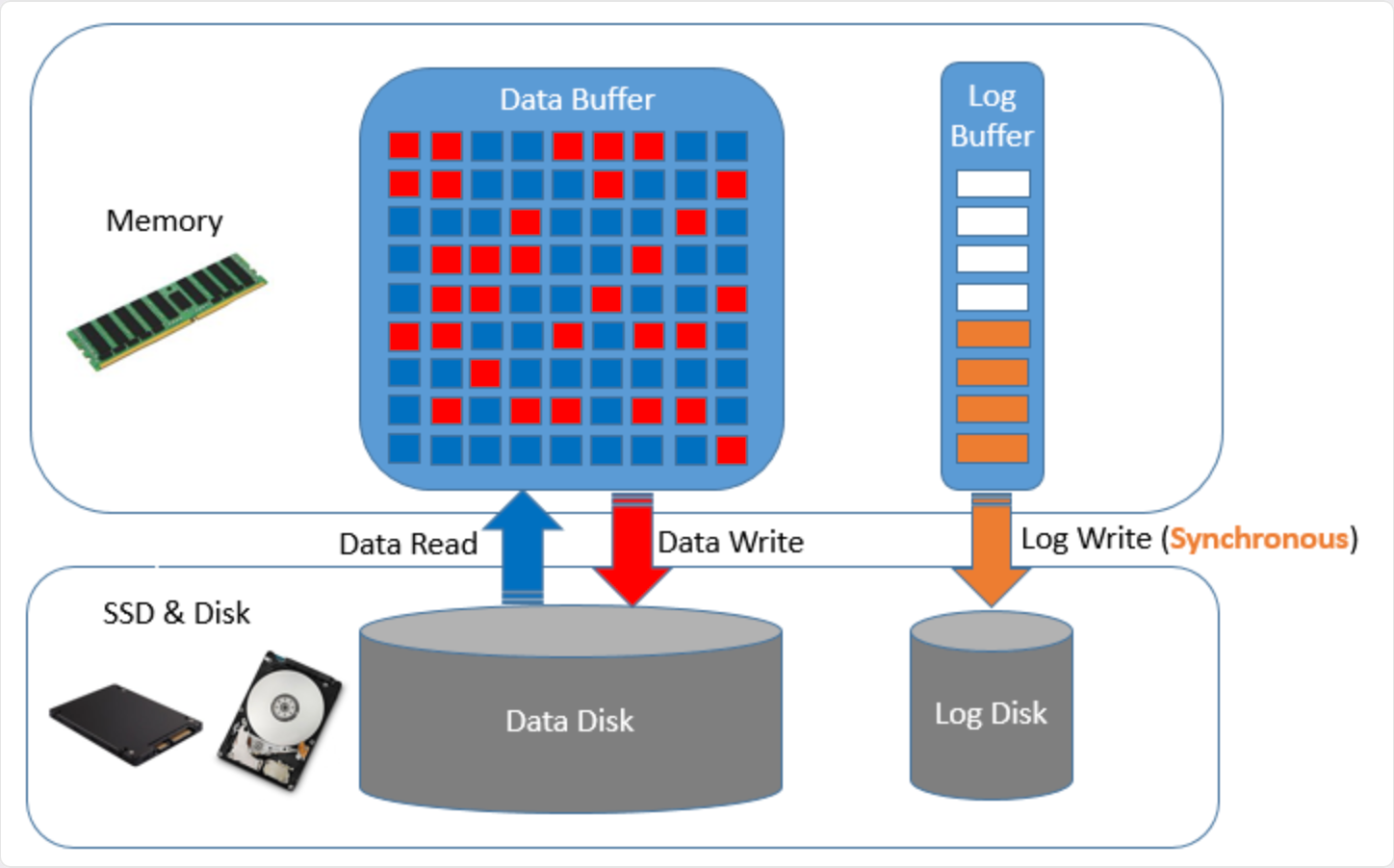
1. LGWR 的 I/O 特性
? 順序寫
? 小 I/O
? 對 IOPS 非常敏感
一旦存儲繁忙,LGWR 寫入速度下降,log file sync 就會出現。
判斷方法
方法一:觀察操作系統磁盤負載
? AIX:topas
? Linux:iostat, sar
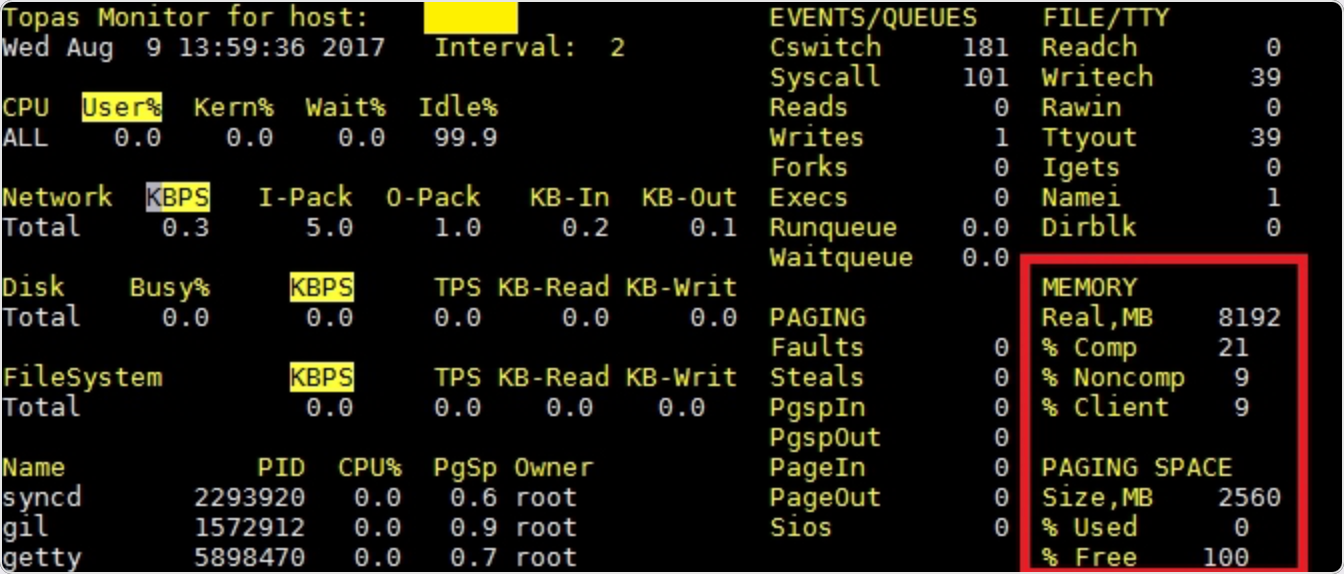
方法二:對比等待事件時間
? log file parallel write
? log file sync
如果兩者時間 接近,說明問題在存儲。
查看等待分布示例
SELECT event, wait_time_milli, wait_count
FROM v$event_histogram
WHERE event = 'log file parallel write';
示例輸出:
WAIT_TIME_MILLI WAIT_COUNT
1 22677
2 424
4 141
8 340
16 1401
32 812
64 391
128 21
256 6
解決方案
1. redo log 遷移到獨立、空閑、性能更高的磁盤
2. 視情況遷移 UNDO 表空間,釋放 I/O 壓力
3. redo log 有多 member 時,可減少 member 數量
原因三:短時間業務量過大(redo 激增)
常見于:
? 批量 DML
? 夜間批處理
? 數據遷移
分析建議
? 分析 redo / archive 生成趨勢
? 判斷是否業務突增而非系統異常
? 觀察業務量是否平穩
原因四:CPU 資源緊張,LGWR 搶不到時間片
現象特征
? log file sync 很高
? log file parallel write 每次僅 1~2ms
說明:
LGWR 寫得并不慢,而是 拿不到 CPU
解決方案
1. 增加 CPU / 優化高 CPU SQL(效果最好,成本最高)
2. OS 層面提高 LGWR 優先級(renice)
3. 綁定 LGWR 到指定 CPU
4. 設置隱含參數:
_high_priority_processes
原因五:redo buffer 太小
? redo buffer 太小 → 寫入過于頻繁
? redo buffer 太大 → 單次寫入量過大
建議
? 適當調大
? 調整后持續觀察
? 不建議一味追求“大”
原因六:redo log 文件太小 / 組數不足
建議配置
? redo 文件大小:
? 至少 500MB
? 繁忙系統建議 1G / 2G
? redo log 組數:
? 至少 3 組
? 繁忙系統建議 5 組以上
四、RAC 場景下的特殊原因
原因七:RAC 節點之間 SCN 同步(Commit SCN)
原理說明
RAC 中為了保證一致性讀,需要同步 commit SCN。
? Lamport SCN
? Immediate Commit Propagation(BOC)
BOC 提交流程
流程簡述:
1. User Session commit
2. LGWR 寫 redo
3. LGWR 將 commit SCN 廣播給遠端 LMS
4. 遠端 LMS 同步 SCN
5. 全部確認后,commit 才返回成功
解決思路
1. 檢查 LMS 進程數量
2. 檢查 CPU 是否足夠
3. 檢查私網通信
4. 必要時關閉 BOC:
_immediate_commit_propagation = false
原因八:RAC 節點之間 CR 塊傳遞
原理
? current block 修改后
? redo 必須寫入完成
? 才能通過 LMS 傳給其他節點
解決方案
1. 減少跨節點訪問
2. 設置:
_cr_server_log_flush = false
原因九:控制文件爭用
LGWR 寫 redo 時需要更新控制文件。
? RMAN 高頻操作
? 并發控制文件更新
? 導致 enq: CF–contention
當 LGWR 拿不到 CF 鎖時,前臺會話可能出現 log file sync。
五、OLTP 系統的一個關鍵參數建議
對于交易型(OLTP)系統:
ALTER SYSTEM SET “_use_adaptive_log_file_sync” = FALSE SCOPE=SPFILE SID=’*’;
含義:
? 固定使用 post/wait 機制
? 避免 adaptive 模式下產生過多 log file sync
六、總結
log file sync 不是一個簡單的“磁盤慢”問題,而是:
事務提交、redo 寫入、CPU 調度、RAC 同步等多因素共同作用的結果。
排查建議:
1. 先看 commit 頻率
2. 再看 log file parallel write
3. 同時結合 CPU、存儲、RAC 架構
4. 避免“只調參數、不看業務”的誤區
它本質上,是 Oracle 作為一臺高度同步系統的真實體現。
