





大家好, 今天和大家分享一個真實生產案例: 異地數據庫同步延時導致的主庫關閉失敗問題。
簡單的說一下背景:
我們要在計劃內部署維護窗口做2件事:
1.ORACLE 遷移到PG的項目,數據同步, 大致幾十個GB的數據(包含索引)。
2.PG 端要做一個小版本的升級,從版本15.2升級到15.3 , 需要執行停庫操作,進行 make install-world , 再重啟數據庫
生產的數據庫架構是: 武漢PDC (1 Primary DB + 2 standby DB) + 天津DRC災備中心 (1 standby DB)
預計窗口停機: 23:00- 00:00 1個小時
部署當天晚上:
1.執行 ORACLE 遷移到PG的項目,數據同步 – 比較順利,和期望是一致的
2.PG實例在關機的時候 出現了命令 pg_ctl stop -D $PG_DATA hang 住,長時間等待的情況。。。
后臺日志出現了大量的關閉失敗的信息
2023-07-17 23:45:05.033 CST [109594] repmgr@repmgr-10.25.14.149/[unknown]FATAL: the database system is shutting down 2023-07-17 23:45:05.035 CST [109595] repmgr@repmgr-10.25.14.149/[unknown]FATAL: the database system is shutting down 2023-07-17 23:45:05.613 CST [109603] capp_lm@cappcore-10.26.212.19/[unknown]FATAL: the database system is shutting down 2023-07-17 23:45:05.822 CST [109605] capp_lm@cappcore-10.26.212.49/[unknown]FATAL: the database system is shutting down
而此時 ps -ef | grep postgres , 后臺進程還是存在的, 但是這個時候嘗試連接 PSQL 也是失敗的
由于維護窗口只有一個小時,時間緊迫,采取了 -m immediate 參數 立刻關閉的方式。 (生產環境不建議這種方式)
pg_ctl stop -D $PG_DATA -m immediate
這下算是順利關機, 然后給PG 軟件小版本升級,然后啟動實例一切順利!
作為運維DBA來說,如果生產如果出現問題,恢復生產的可用性永遠是第一位的, 然后才是調查 root cause.
初步懷疑原因: 和主從延時有關,異地網絡的傳輸效率比較差, wal sender 進程 blocking the 主庫關閉.
我們可以找個測試環境來復盤這個問題:
測試環境模擬 1 主 : pref170+ 2從: pref171,pref173 +1從: pgdr(異地)
postgres=# select pid,usename,application_name,replay_lag,reply_time from pg_stat_replication;
pid | usename | application_name | replay_lag | reply_time
--------+---------+------------------+-----------------+-------------------------------
22250 | repmgr | pref173 | 00:00:00.000816 | 2023-08-19 10:43:49.650063+08
22252 | repmgr | pref171 | 00:00:00.000923 | 2023-08-19 10:43:49.650243+08
126245 | repmgr | pgdr | 00:00:00.020848 | 2023-08-19 10:43:49.661431+08
(3 rows)
登錄主庫 pref170: 模擬數據大量數據導入8000W數據,造成主從延時。
postgres=# create table t_load (id bigint, context text);
CREATE TABLE
postgres=# insert into t_load select generate_series(1,80000000),md5('a')||md5('b')||md5('c')||md5('d')||md5('e');
INSERT 0 80000000
查看延時: 異地節點延時grafana 監控圖 同步lag 已經達到了 10分鐘以上
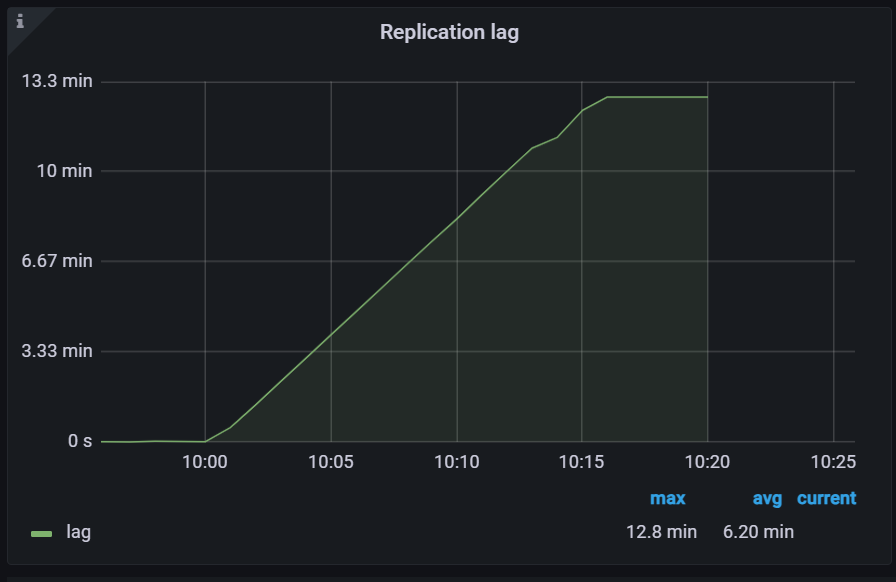
我們嘗試關閉主庫:
INFRA [postgres@ljzdccapp006 ~]# /opt/pgsql-15/bin/pg_ctl stop -D /data/pref6005/data
waiting for server to shut down............................................................... failed
pg_ctl: server does not shut down
查看主庫后臺進程:果然是walsender 進程健在,指向的同步節點是異地DC的機器
INFRA [postgres@ljzdccapp006 ~]# ps -ef | grep postgres
postgres 13444 1 0 Aug19 ? 00:01:07 /opt/pgsql-15/bin/postgres -D /data/pref6005/data
postgres 17151 13444 0 Aug19 ? 00:00:40 postgres: pref170: walsender repmgr 10.25.15.85(54434) streaming C/F5F06000
我們嘗試再次登陸關閉未成功的主庫:數據庫的狀態是 shutting down ,不允許建立任何連接
INFRA [postgres@ljzdccapp006 ~]# psql
psql: error: connection to server on socket "/tmp/.s.PGSQL.6005" failed: FATAL: the database system is shutting down
查看主庫日志: 也全部都是 the database system is shutting down , 數據庫連接失敗的信息
2023-08-20 10:21:40.162 CST [96140] repmgr@[unknown]-10.67.38.171/[unknown]FATAL: the database system is shutting down 2023-08-20 10:21:40.211 CST [96141] [unknown]@[unknown]-10.67.38.173/[unknown]LOG: connection received: host=10.67.38.173 port=56246 2023-08-20 10:21:40.212 CST [96141] repmgr@[unknown]-10.67.38.173/[unknown]FATAL: the database system is shutting down 2023-08-20 10:21:40.282 CST [96143] [unknown]@[unknown]-10.67.38.173/[unknown]LOG: connection received: host=10.67.38.173 port=56248 2023-08-20 10:21:40.283 CST [96143] repmgr@repmgr-10.67.38.173/[unknown]FATAL: the database system is shutting down 2023-08-20 10:21:40.284 CST [96144] [unknown]@[unknown]-10.67.38.173/[unknown]LOG: connection received: host=10.67.38.173 port=56250 2023-08-20 10:21:40.284 CST [96144] repmgr@repmgr-10.67.38.173/[unknown]FATAL: the database system is shutting down
至此我們完全模擬了生產由于跨DC延時,關閉主庫hang 住關閉失敗的情況, 果然是后臺進程walsender blocking了實例的關閉。
我們更近一步,從源碼的角度看一下為什么 walsender 進程會阻礙了 shutdown process.
我們執行的關閉命令: /opt/pgsql-15/bin/pg_ctl stop -D /data/pref6005/data, 對應的后臺代碼是 pg_ctl.c 的 do_stop(void)
kill((pid_t) pid, sig) 向后臺linux 系統發送 kill 的信號量: #define SIGINT 2 /* Interrupt (ANSI). */
static void
do_stop(void)
{
pgpid_t pid;
pid = get_pgpid(false);
if (pid == 0) /* no pid file */
{
write_stderr(_("%s: PID file \"%s\" does not exist\n"), progname, pid_file);
write_stderr(_("Is server running?\n"));
exit(1);
}
else if (pid < 0) /* standalone backend, not postmaster */
{
pid = -pid;
write_stderr(_("%s: cannot stop server; "
"single-user server is running (PID: %ld)\n"),
progname, pid);
exit(1);
}
if (kill((pid_t) pid, sig) != 0)
{
write_stderr(_("%s: could not send stop signal (PID: %ld): %s\n"), progname, pid,
strerror(errno));
exit(1);
}
if (!do_wait)
{
print_msg(_("server shutting down\n"));
return;
}
else
{
print_msg(_("waiting for server to shut down..."));
if (!wait_for_postmaster_stop())
{
print_msg(_(" failed\n"));
write_stderr(_("%s: server does not shut down\n"), progname);
if (shutdown_mode == SMART_MODE)
write_stderr(_("HINT: The \"-m fast\" option immediately disconnects sessions rather than\n"
"waiting for session-initiated disconnection.\n"));
exit(1);
}
print_msg(_(" done\n"));
print_msg(_("server stopped\n"));
}
}
我們看看 后臺主進程 postmaster 怎么處理這個信號量: postmaster.c -> pmdie(SIGNAL_ARGS)
/*
* pmdie -- signal handler for processing various postmaster signals.
*/
static void
pmdie(SIGNAL_ARGS)
{
case SIGINT:
/*
* Fast Shutdown:
*
* Abort all children with SIGTERM (rollback active transactions
* and exit) and shut down when they are gone.
*/
if (Shutdown >= FastShutdown)
break;
Shutdown = FastShutdown;
ereport(LOG,
(errmsg("received fast shutdown request")));
/* Report status */
AddToDataDirLockFile(LOCK_FILE_LINE_PM_STATUS, PM_STATUS_STOPPING);
#ifdef USE_SYSTEMD
sd_notify(0, "STOPPING=1");
#endif
if (pmState == PM_STARTUP || pmState == PM_RECOVERY)
{
/* Just shut down background processes silently */
pmState = PM_STOP_BACKENDS;
}
else if (pmState == PM_RUN ||
pmState == PM_HOT_STANDBY)
{
/* Report that we're about to zap live client sessions */
ereport(LOG,
(errmsg("aborting any active transactions")));
pmState = PM_STOP_BACKENDS;
}
/*
* PostmasterStateMachine will issue any necessary signals, or
* take the next step if no child processes need to be killed.
*/
PostmasterStateMachine();
break;
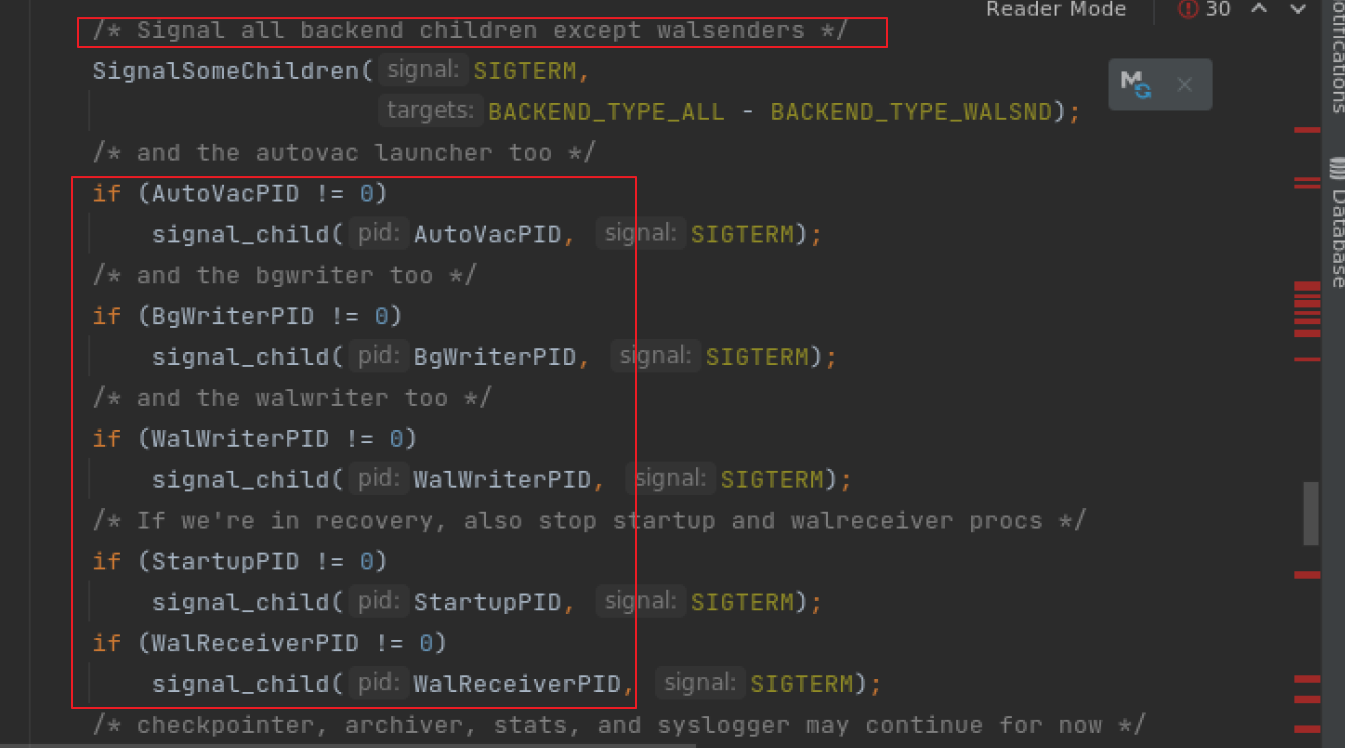
關閉postmaster 主進程下所有子進程函數: postmaster.c -> static void PostmasterStateMachine(void)
我們可以看到 /* Signal all backend children except walsenders */ , 一幕了然, 也從源碼的角度證實了walsenders 進程號是不會被發送信號量 kill掉的
寫到最后總結:
1)如果數據庫存在異地部署且網絡不佳的狀況,關閉主庫前需要檢查數據庫延時的lag : select pid,usename,application_name,replay_lag,reply_time from pg_stat_replication;
2)遇到數據庫維護重啟+數據遷移任務: 可以調整順序1. 數據庫維護重啟 2. 執行大量數據任務
3)如果上訴1,2步驟不小心忽略了, 可以嘗試直接關閉有延時的異地從庫,這樣主庫進程 walsender 自然會關閉, postmaster 主進程也隨之關閉。
Have a fun ?? !
